High tech
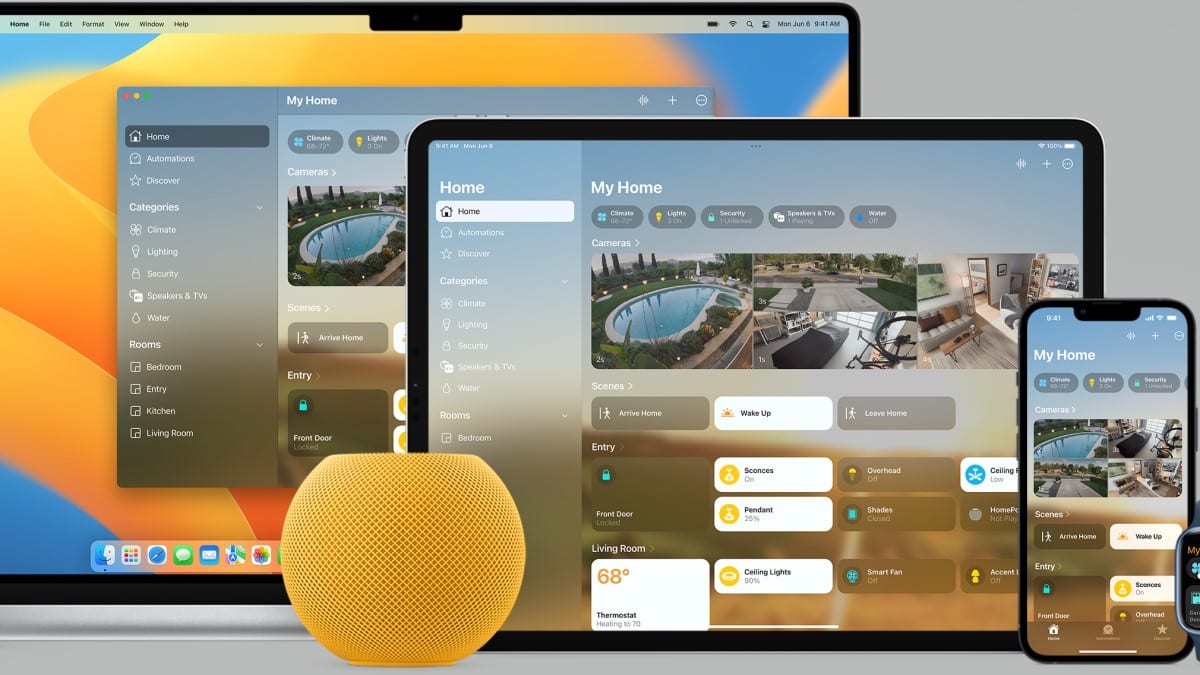
Comment protéger sa maison avec l’application Apple HomeKit ?
L’application Apple HomeKit révolutionne la sécurité domestique en permettant aux utilisateurs de transformer leur maison en un havre de paix technologiquement avancé. Grâce à une …
Lire plus
Manette PS5 Asymétrique : découverte de la manette Nacon
Depuis la création des premières consoles de jeu, les manettes ont connu une évolution afin de répondre aux besoins des joueurs. En effet, avec ces …
Lire plus
Comment optimiser la lumière des images créées par DALL·E 3 ?
Optimiser l’éclairage dans les images générées par DALL·E 3 peut transformer une création ordinaire en une œuvre visuellement impressionnante. Ce guide explore des techniques avancées …
Lire plus
Quelle solution de sauvegarde pour éviter de perdre ses photos et vidéos ?
Pour garantir la sécurité de vos précieuses photos et vidéos, il est essentiel de mettre en place une stratégie de sauvegarde efficace. Cet article explore …
Lire plus
Comment localiser un iPhone volé ou perdu avec iCloud ?
Perdre ou se faire voler son iPhone peut être une expérience angoissante, mais grâce à iCloud, il existe des moyens efficaces pour tenter de localiser …
Lire plusAndroid





Téléphone

Comment nettoyer un smartphone tombé dans le sable ou dans l’eau ?
Votre smartphone a malencontreusement rencontré le sable ou l’eau ? Pas de panique ! Ce guide détaillé vous offre une méthode étape par étape pour …